How fast can you read a very large csv file and compute min, max, average aggregation out of it (Part 1)
Here’s a coding challenge: how fast can you compute simple calculations from values read from a very very very large csv file… in Java ! Reading (large) files is a common problem every developer has to solve once in his life. Providing a quick solution is easy and takes a couple of minutes but providing an efficient solution is harder. Effectiveness is a relative concept but if you like to do things the best way you can in that case we can say it is the capability of producing a solution you are proud of and are not ashamed of publishing (“Talk is cheap, show me the code”).

In this example, the csv file looks like this, generated by the class CsvGenerator (repository). It contains 6 columns:
- Year: an integer ranging from 1990 to 2021
- Mileage: an integer ranging from 1000 to 300,000 (kilometers)
- Selling price: a float/double number ranging from 1000 to 100,000 (dollars)
- Brand: a string, e.g Volvo, Audi…
- Transmission: a string that can be either ‘M’ (Manual) or ‘A’ (Automatic)
- Fuel type: a string that can be either ‘petrol’ or ‘diesel’
1993,32534,20124.10793005441,Lamborghini,A,diesel
2017,215165,59169.718001828034,abarth,M,diesel
1992,140313,7395.174281748225,Porsche,M,diesel
2000,46953,28162.09251937553,dacia,M,petrol
2009,279057,46607.34037365823,hyundai,M,petrol
2006,259618,31907.168909384665,lotus,A,petrol
2014,84975,57477.59584120297,Land Rover,A,petrol
1996,112406,94044.83448517171,Acura,M,petrol
...We assume the csv content is “clean” and simple (which it’s not realistic I agree): no value is missing, delimiter character is ,(comma), no escape character…
The challenge is straightforward. Compute the following values:
- The average mileage
- The average price
- The minimum and maximum values of year, mileage and price
with one condition: for cars build after 2005 i.e year ≥ 2005.
For the benchmarks, I use my laptop, a MacBook Pro (16-inch, 2019) with a 2.6 GHz 6-Core Intel Core i7 processor, a Apple NVMe SSD, model AP0512M. The csv file is 1.55GB big and has approximately 33,5 millions lines. Benchmarks are run with Java 17 (Eclipse Temurin 17).
Naive approach
The first step in this kind of exercise is to always start with the simplest and naive approach and iterate from it. Remember that:
The real problem is that programmers have spent far too much time worrying about efficiency in the wrong places and at the wrong times; premature optimization is the root of all evil (or at least most of it) in programming.
What it does is very simple:
- Read line by line the file
- For each line, break it into pieces to retrieve the values of every fields
- Parse the first three values and aggregate them to the previous computed aggregates
The average aggregation is computed at the end by dividing sumMileage and sumPrice by count
Here’s the result:
Average test time: 13305.5msBy taking a flight recording with jmc (Java Mission Control) during the benchmark, we can analyze where most of the time is spent:
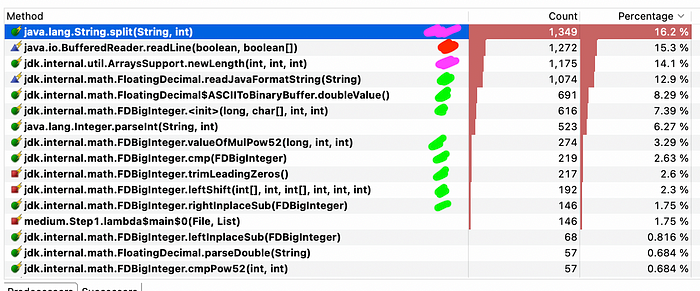
We can see 3 main tasks are consuming most of the CPU:
- Purple: splitting of a line
- Red: reading of the file
- Green: Parsing of the 3rd field (price) from String to double
A look to the memory tab also shows that splitting and parsing generate a lot of allocations
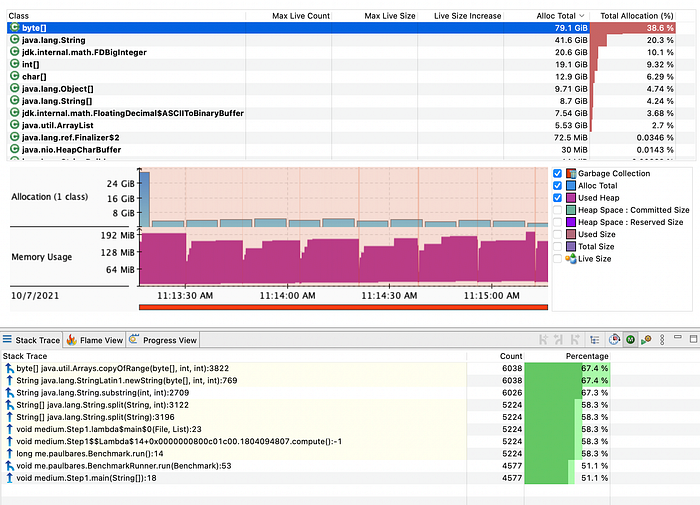
To improve the performance, let’s see how we can avoid the cost of splitting and parsing or at least reducing it.
FastDoubleParser
To reduce the parsing time and limit the object allocations, we can use the straight forward C++ to Java port of Daniel Lemire’s fast_double_parser available here.
(source)
Parsing strings into binary numbers (IEEE 754) is surprisingly difficult. Parsing a single number can take hundreds of instructions and CPU cycles, if not thousands. It is relatively easy to parse numbers faster if you sacrifice accuracy (e.g., tolerate 1 ULP errors), but we are interested in “perfect” parsing.
Instead of trying to solve the general problem, we cover what we believe are the most common scenarios, providing really fast parsing. We fall back on the standard library for the difficult cases. We believe that, in this manner, we achieve the best performance on some of the most important cases.
The change at this step is only from:
Double.parseDouble(values[2])to
FastDoubleParser.parseDouble(values[2]);The result is surprisingly better:
Average test time: 8827.57ms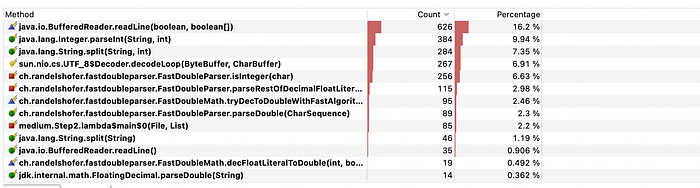
Parsing doubles has now less impact.
Note: I benchmarked first with the library Javolution (replacement of java.lang.Double#parseDouble by javolution.TypeFormat#parseDouble) but the average test time went down to 10947ms only.
Splitter
An obvious optimization to avoid the cost of String#split is to use another library. Let’s try using Splitter from the Guava library as suggested on StackOverflow.
Result:
Average test time: 6730.14msWoW!! It is way better. Average test time has been reduced by 24%! But even if it is very good, let’s profile it.
As you can see on the below screenshot, a lot of String allocation is due to the Splitter. If we could totally get rid of it, it could improve the throughput of the application by reducing the pressure on the heap.
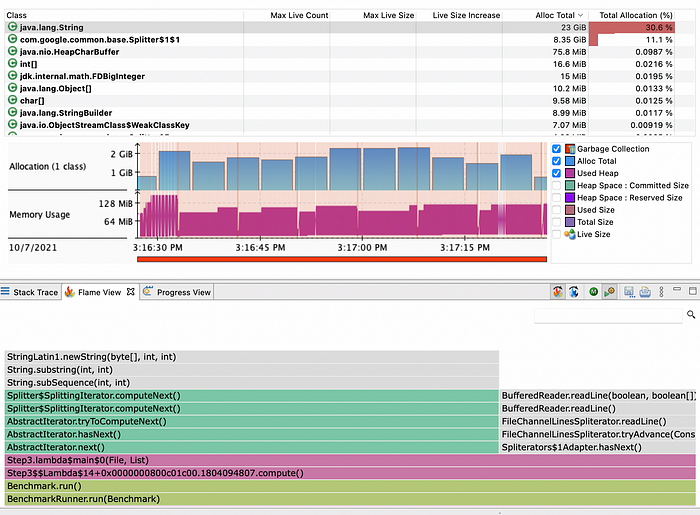
Moreover, a huge amount of time is still spent in splitting the line into pieces.

Can we avoid the String allocations and reduce the amount of time spend breaking a line into pieces? YES ! If we do all the reading by hand meaning opening the file and starting to read it byte per byte to extract only what we are interested in. By doing so, we could avoid copying several time the same information and get rid of String allocations we see in the flight recording (one for a line and one for each different values composing the line including values we don’t care about since we only want the first three values).
Furthermore, we know file contains only ASCII character so it should not be difficult. We use a char array as a buffer and a custom implementation of CharSequence in order to be able to use the methodsInteger#parseInt and FastDoubleParser#parseDouble. The implementation uses the char array buffer to avoid recreating a new object and a new array each time.
Average test time: 6194.71msAverage test time has been reduced by 7%! A flight recording now shows that most of the time is spent trying to parse prices into double.
Note: As you can see, I use a buffer of 64KiB. I tried with different sizes (from 64KiB to 4MiB without any significant changes)
In the end, after a bit work, we end up with a solution 54% faster than the original solution.
In the next part, we’ll see how we can improve even more the performance and compute the result faster. There are two optimizations we will try:
- Branch prediction elimination
- Multi-threading
Claps and shares are very much appreciated!
Full code is available here https://github.com/paulbares/fast-calculation. Note the code snippets in this article can differ a little from the code in the repository.
